
无标题
title:DIFFUSION
date:2025-11-4
DIFFUSION
The sculpture is already complete within the marble block, before I start my work. lt isalready there, I just have to chisel away the superfluous material. - Michelangelo
雕像本来就已经在大理石里面,我只是把不要的部分去掉
Denoise Diffusion Model原理
- 运作流程:
- 从高斯分布中采样一张和最终生成图片同样大小的噪声图片
- reverse process:通过多次Denoise来去除杂讯,逐步雕刻出最终图片
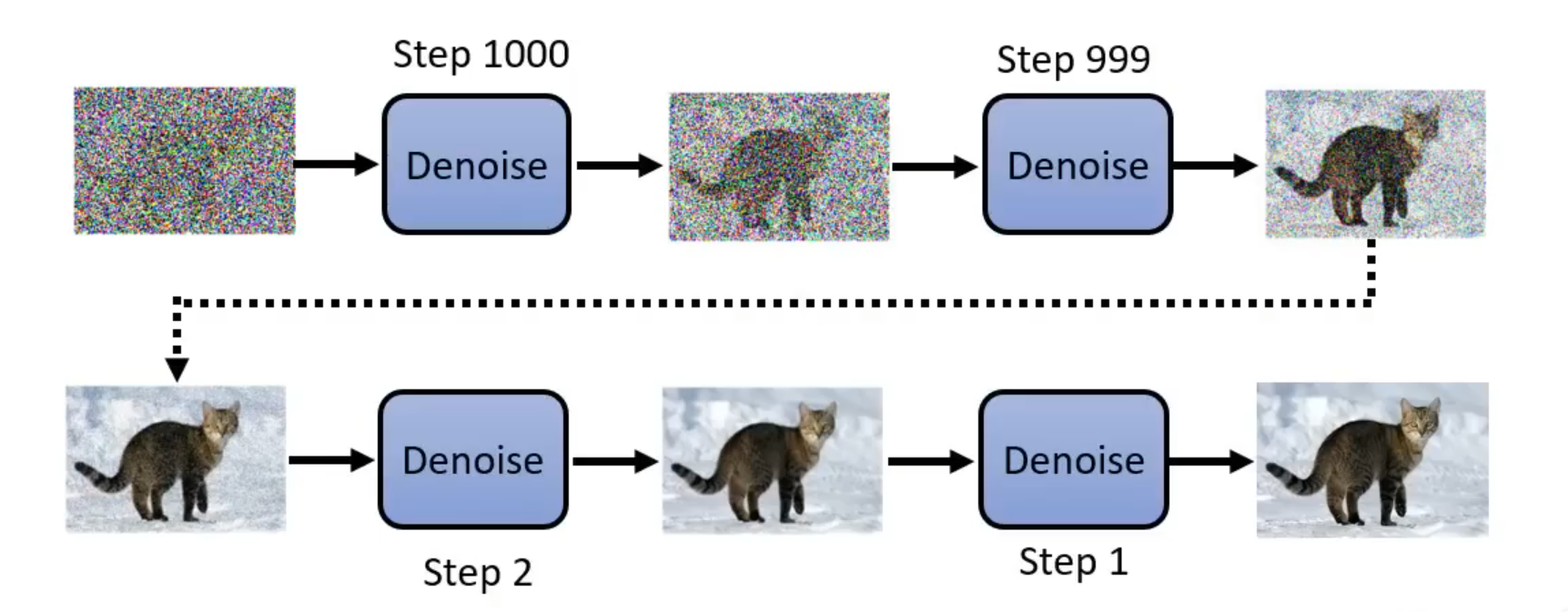
- Denoise Model

输入:除了输入当前含有噪声的图片,还需要输入现在noise严重的程度,根据不同的noise程度做出不同回应
内部结构:存在一个Noise Predicter
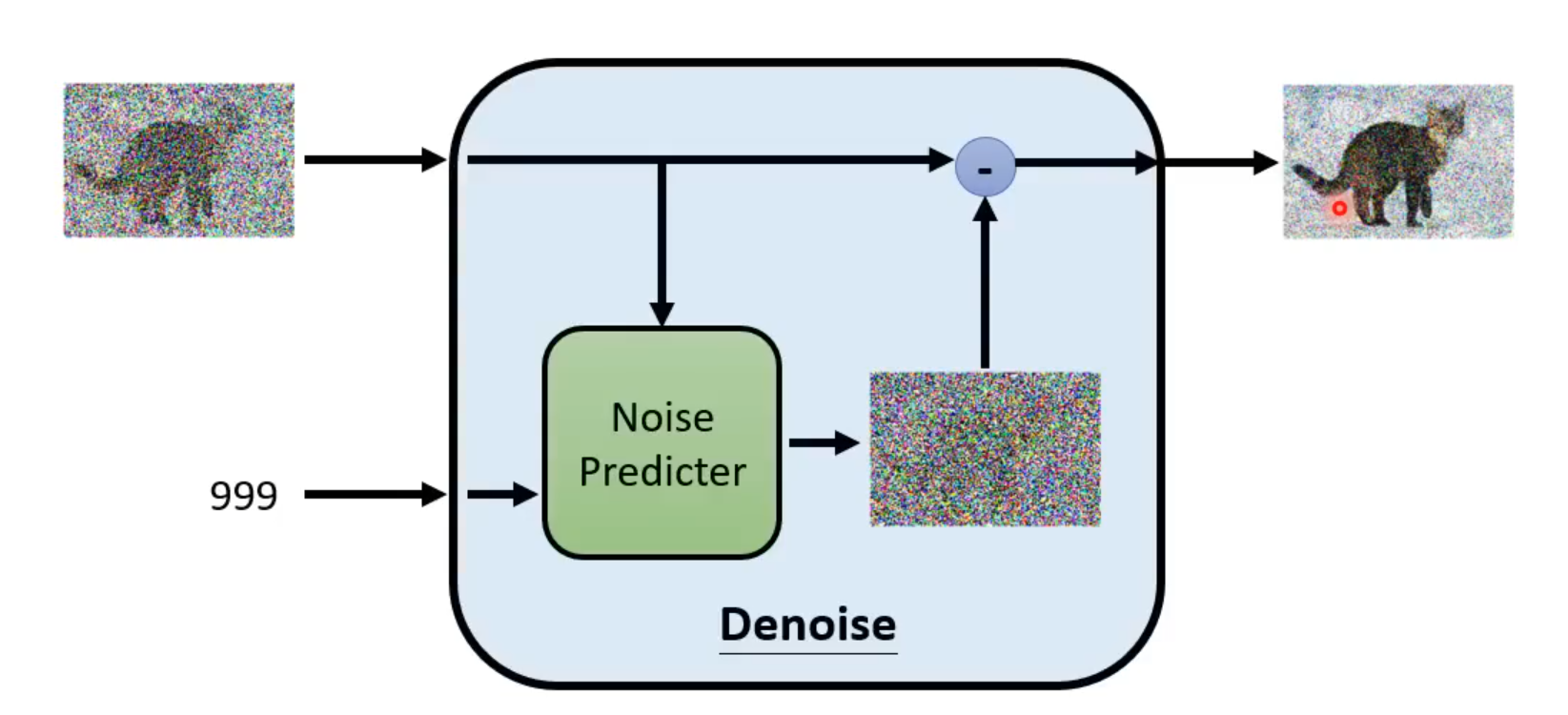
Noise Predicter:用于预测这张图片中的噪声长什么样
输入含噪声图片和目前噪声严重的程度,输出预测的图片杂讯
最终输入图片减去Noise Predicter预测的杂讯,得到这一步的输出
Noise Predicter的训练:
面临的问题:如何获取Noise Predicter的训练资料?
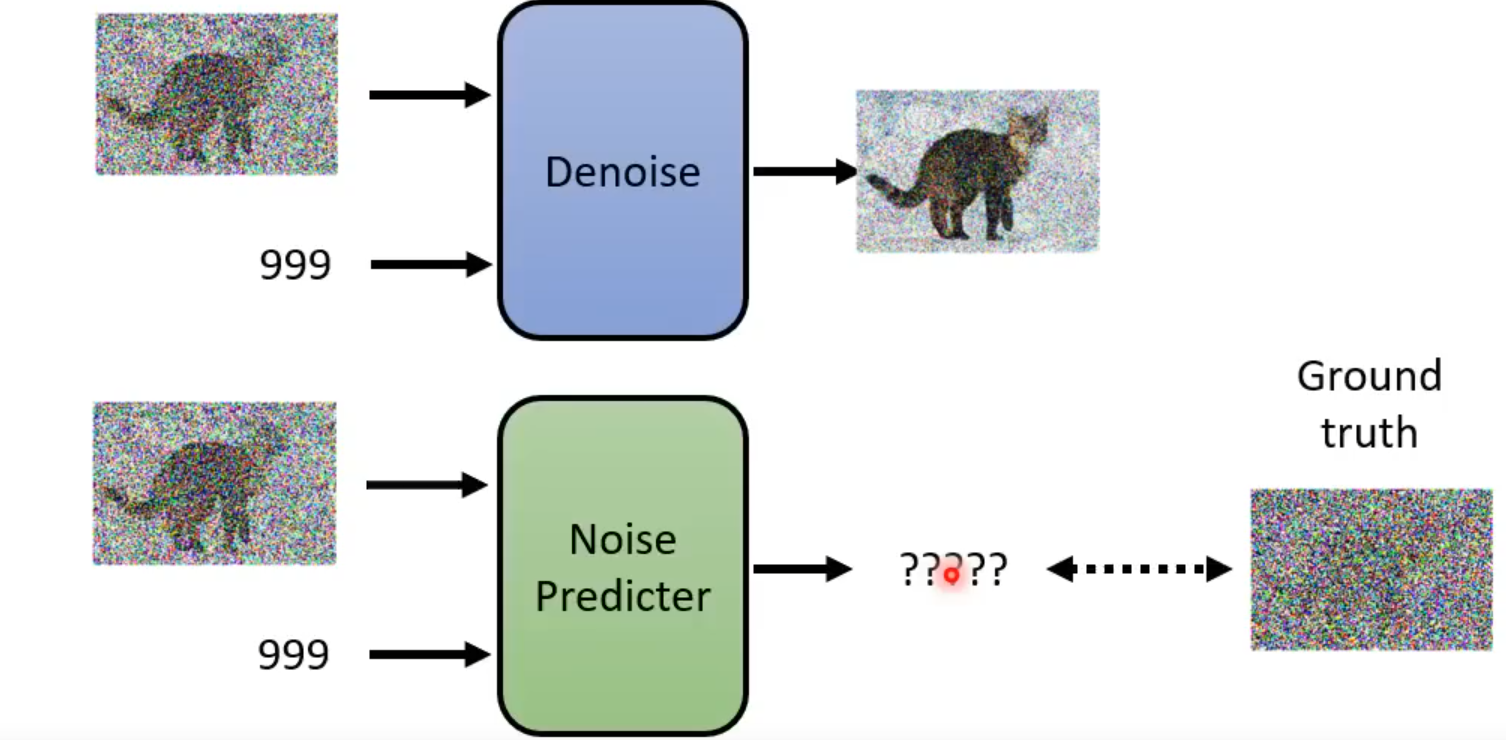
做法:人为对一张图片逐步加噪声
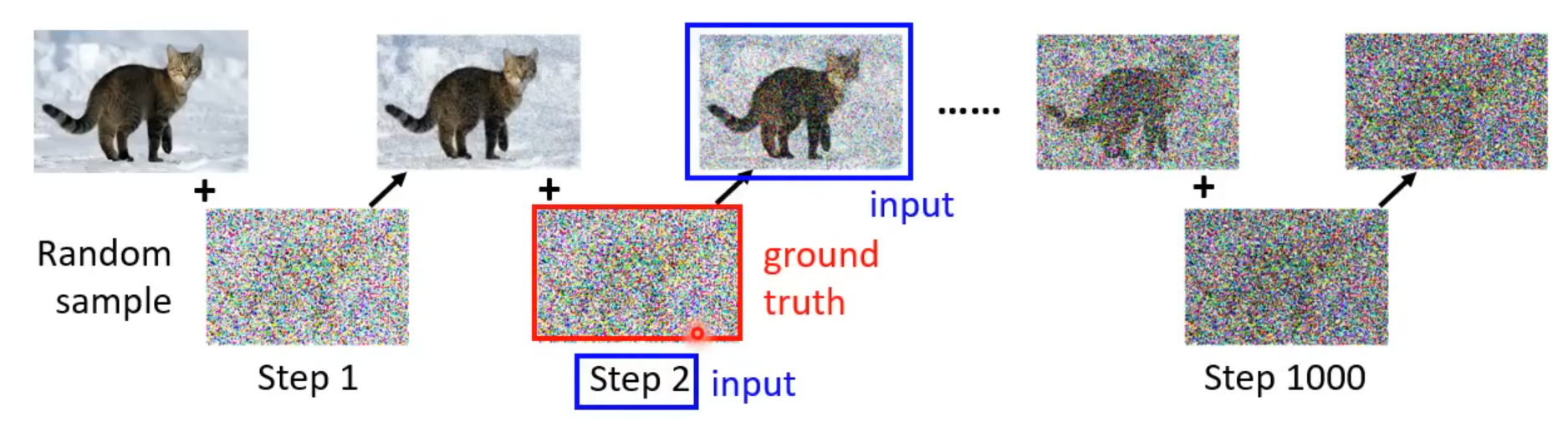
在对这张图片逐步添加噪声的过程中,每一步都可以作为Noise Predicter的训练资料,加完噪声的图片和当前步骤为Noise Predicter的输入,添加的噪声图片为Noise Predicter正确的输出
上述只是从噪声中产生图片,没有考虑文字。
如果要考虑文字生成图片:
训练资料:文字和图片成对
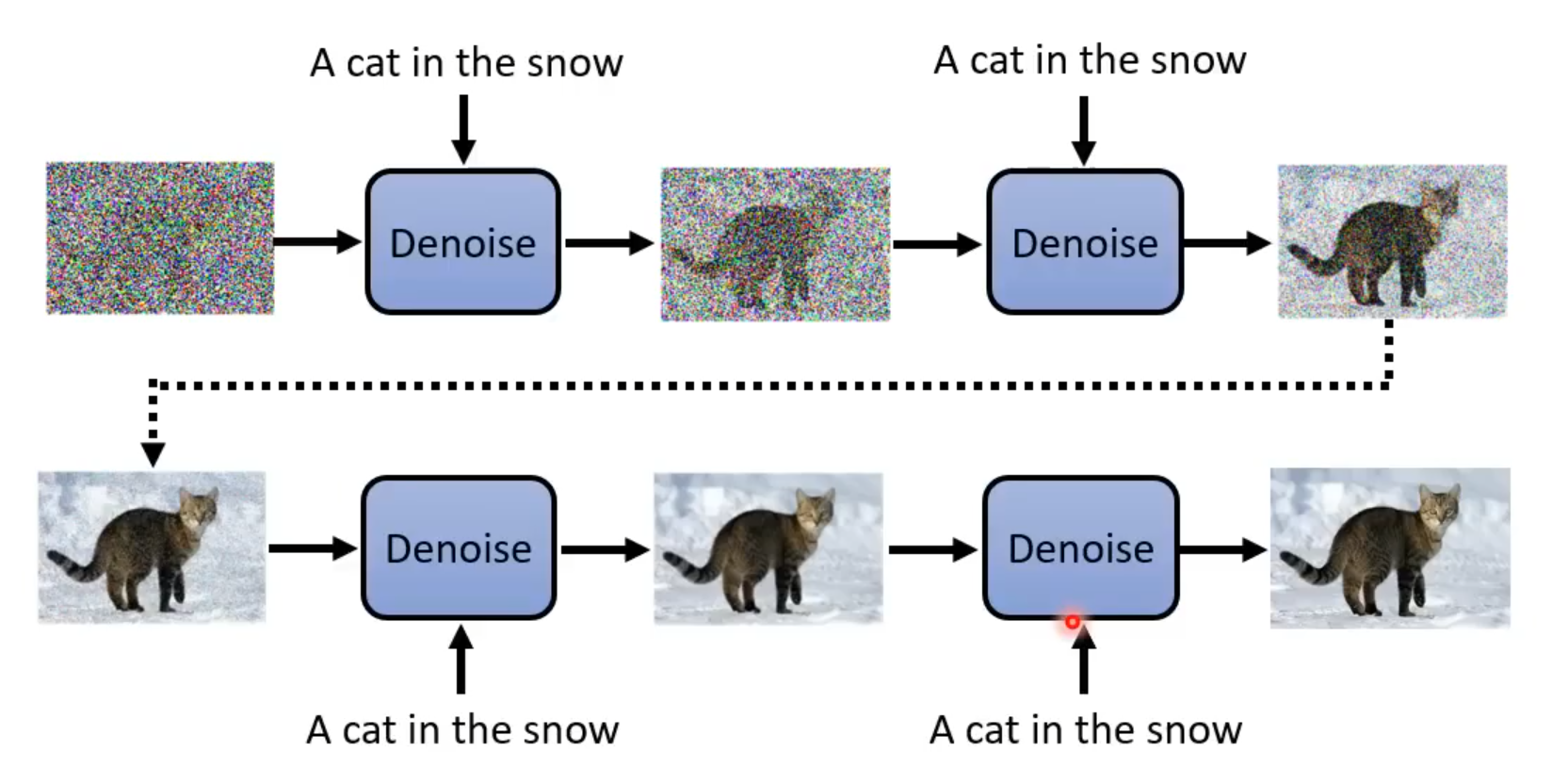
Denoise的运行只是多了一段文字输入,原理一样
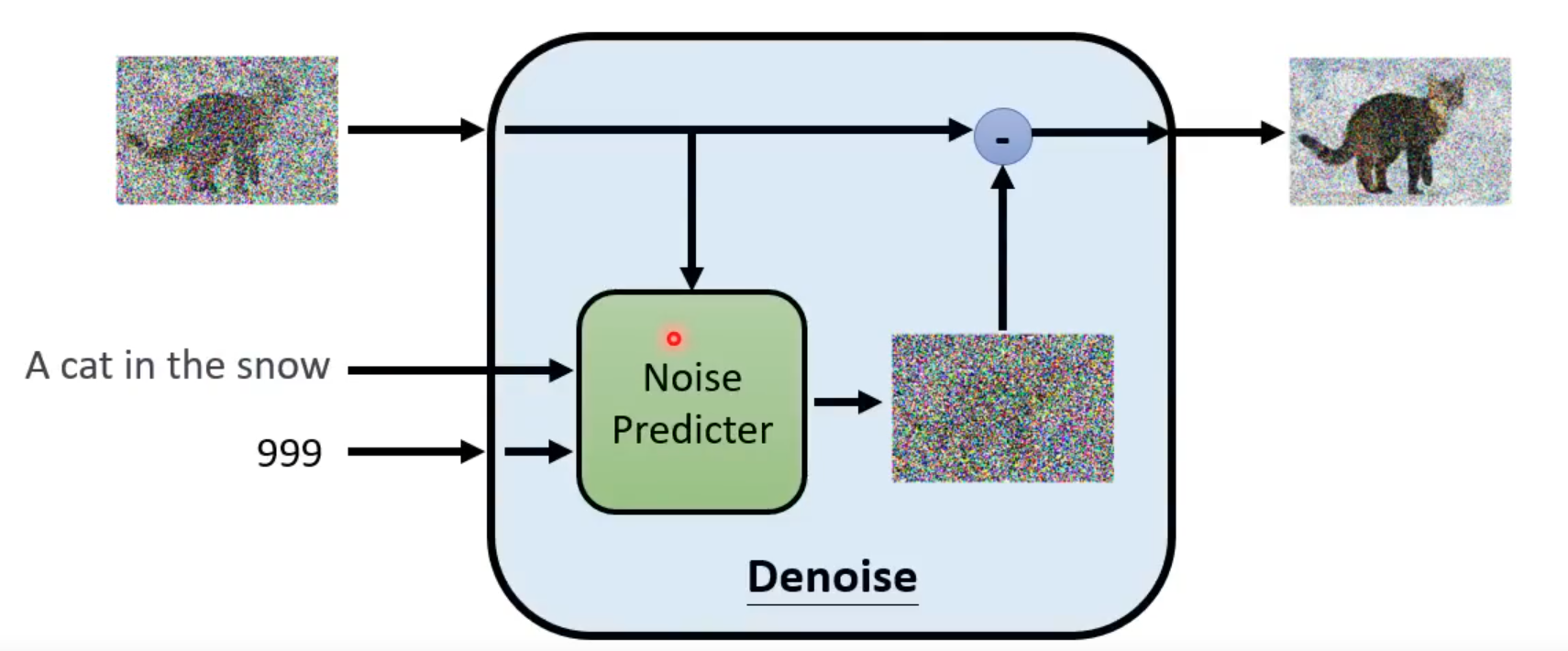
Noise Predicter同样也是多了文字输入

在训练过程中同样也是每一步添加一段文字输入
Stable Diffusion
三大元件:
1. Text Encoder
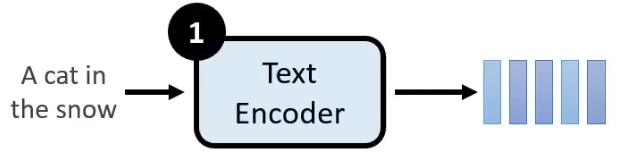
- Text Encoder作用是将文字叙述转换为向量,这部分可以用GPT、BERT等等模型来完成
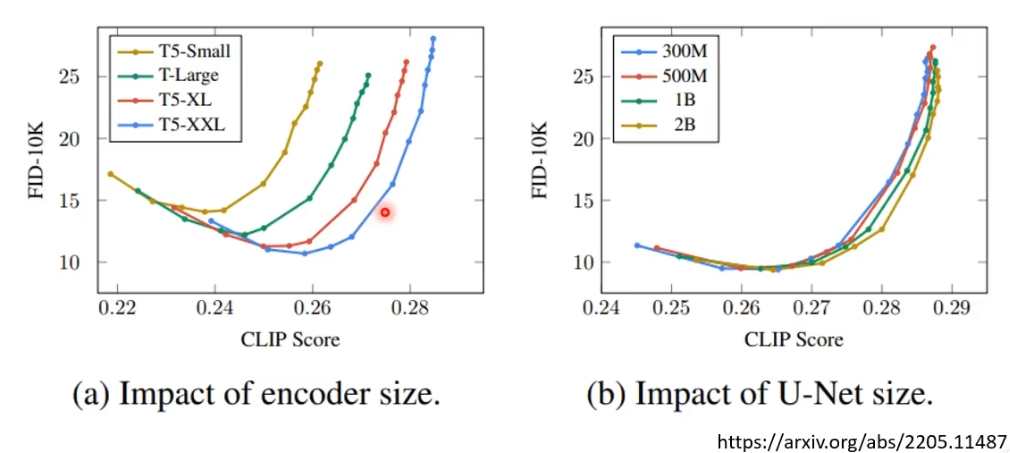
- Encoder对于结果的好坏影响非常大,相对而言diffusion model的大小就没有那么重要
2. Generation Model
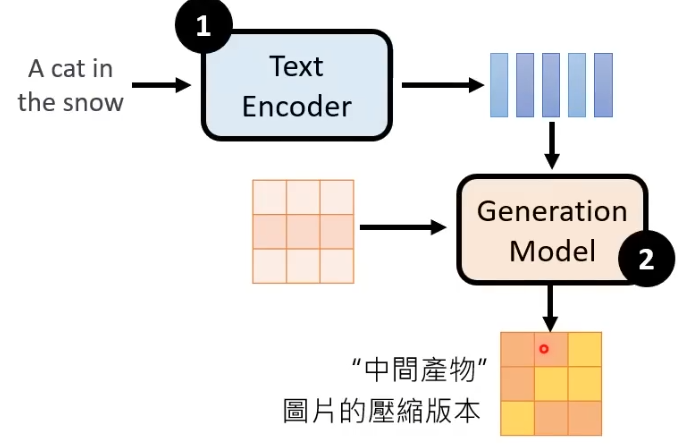
输入为Text Encoder产生的向量以及一个杂讯图片,输出“中间产物”:图片的压缩版本
具体流程:从一个正态分布中sample出一个噪音图片,和Encoder产生的向量一起构成输入,和前面类似的使用Denoise模块来进行逐步的噪声消除,最终将生成的“中间产物”交给Decoder
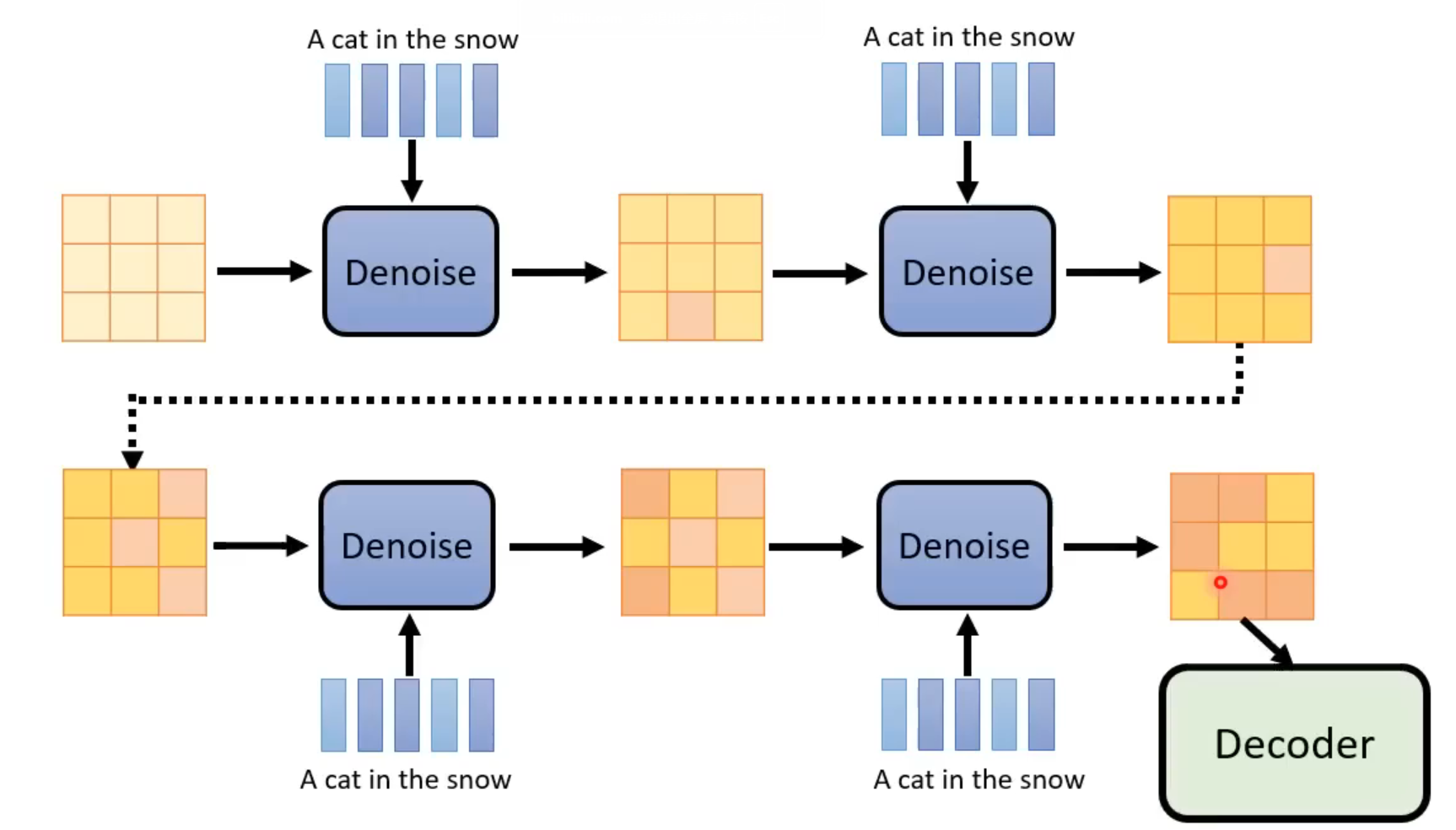
Generation Model的训练过程:
- 数据集准备:和前面的Denoise Diffusion Model不同的是,这里的diffusion model产生的不是图片,而是要传给Decoder的“中间产物”,因此,noise现在要加到“中间产物”上
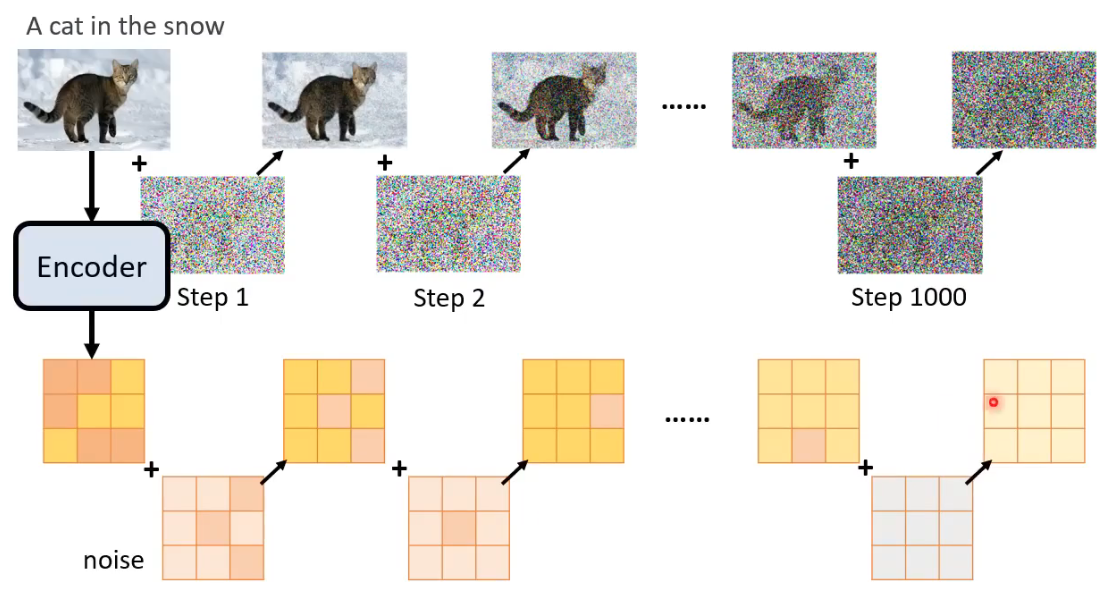
这里的Encoder和前面的Text Encoder不同,这里的Encoder是和Decoder训练时一同产生的Encoder,可以将图片变成“中间产物”(这里以“中间产物”是Latent Representation为例),对于Encoder输入图片后产生的“中间产物”,逐步对其添加噪声,最后得到一个完全从噪声中sample出来的向量,这就是训练集的准备过程
- Noise Predicter训练
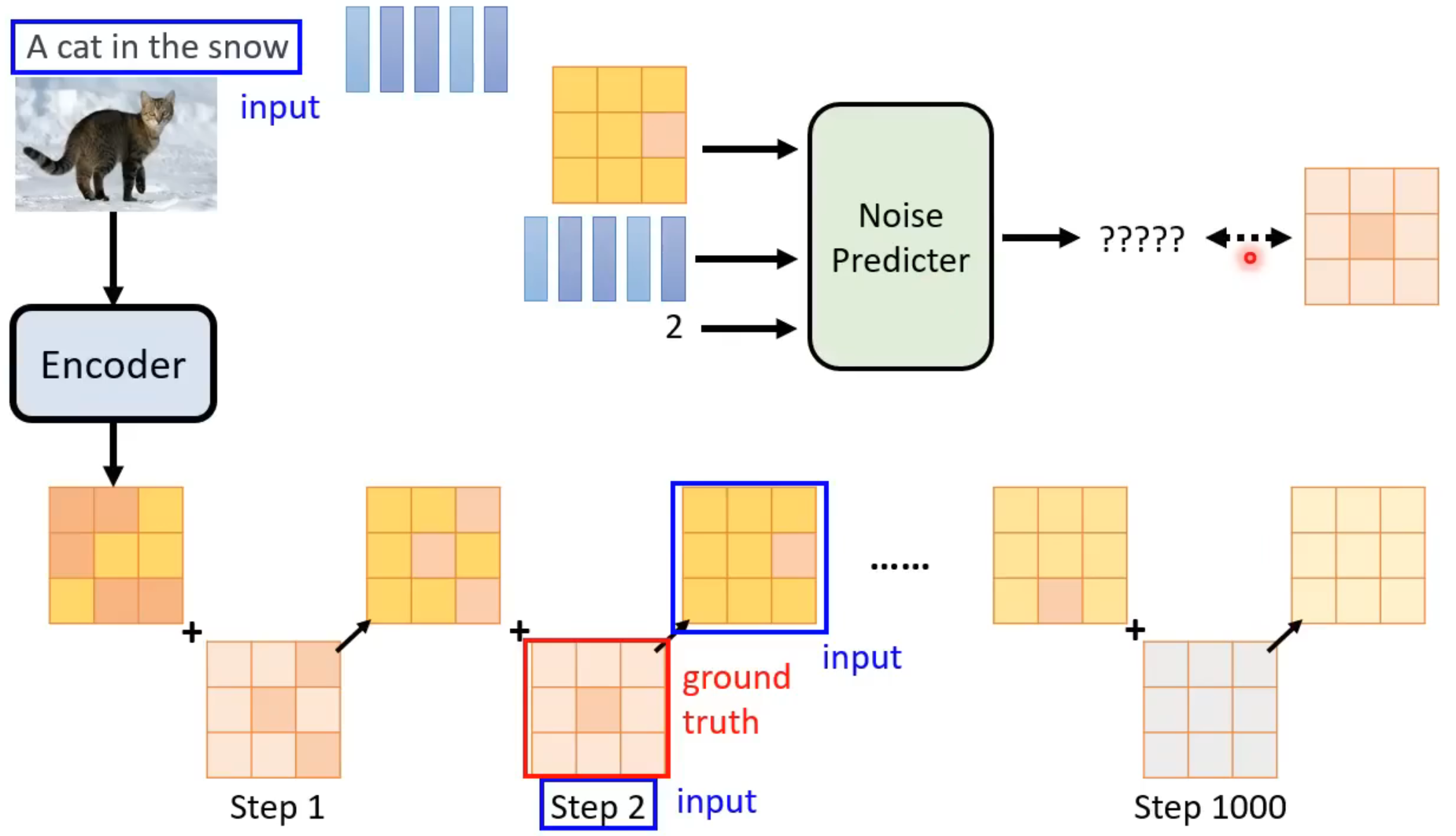
和前面类似,不过这里的输入不是图片+文字+步骤,而是Latent Representation+文字+步骤,输出依旧是噪声。通过对noise predicter的训练,就可以得到denoise模块,输入噪声+文字,输出”中间产物“
3. Decoder
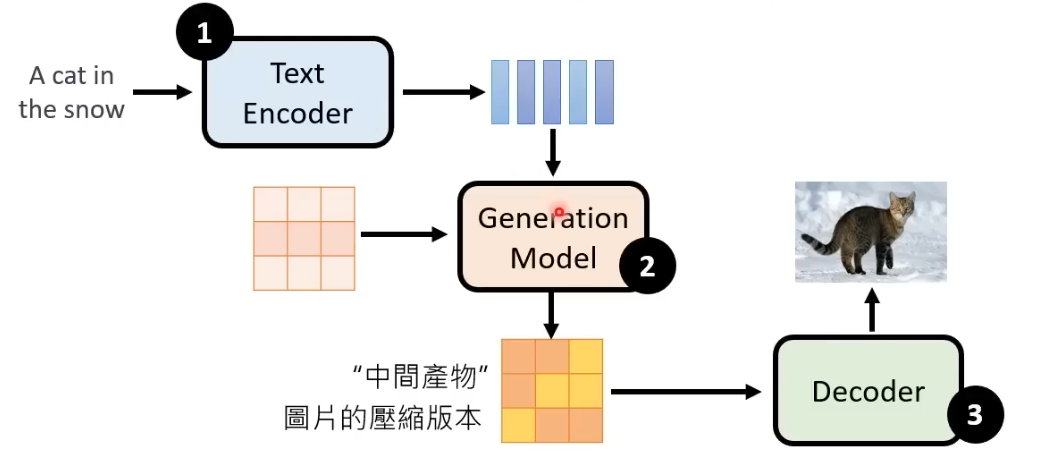
将图片的压缩版本还原回原来的图片。
训练时不需要文字-图片对,训练集准备分为以下几种情况:
- “中间产物”为小图(如:
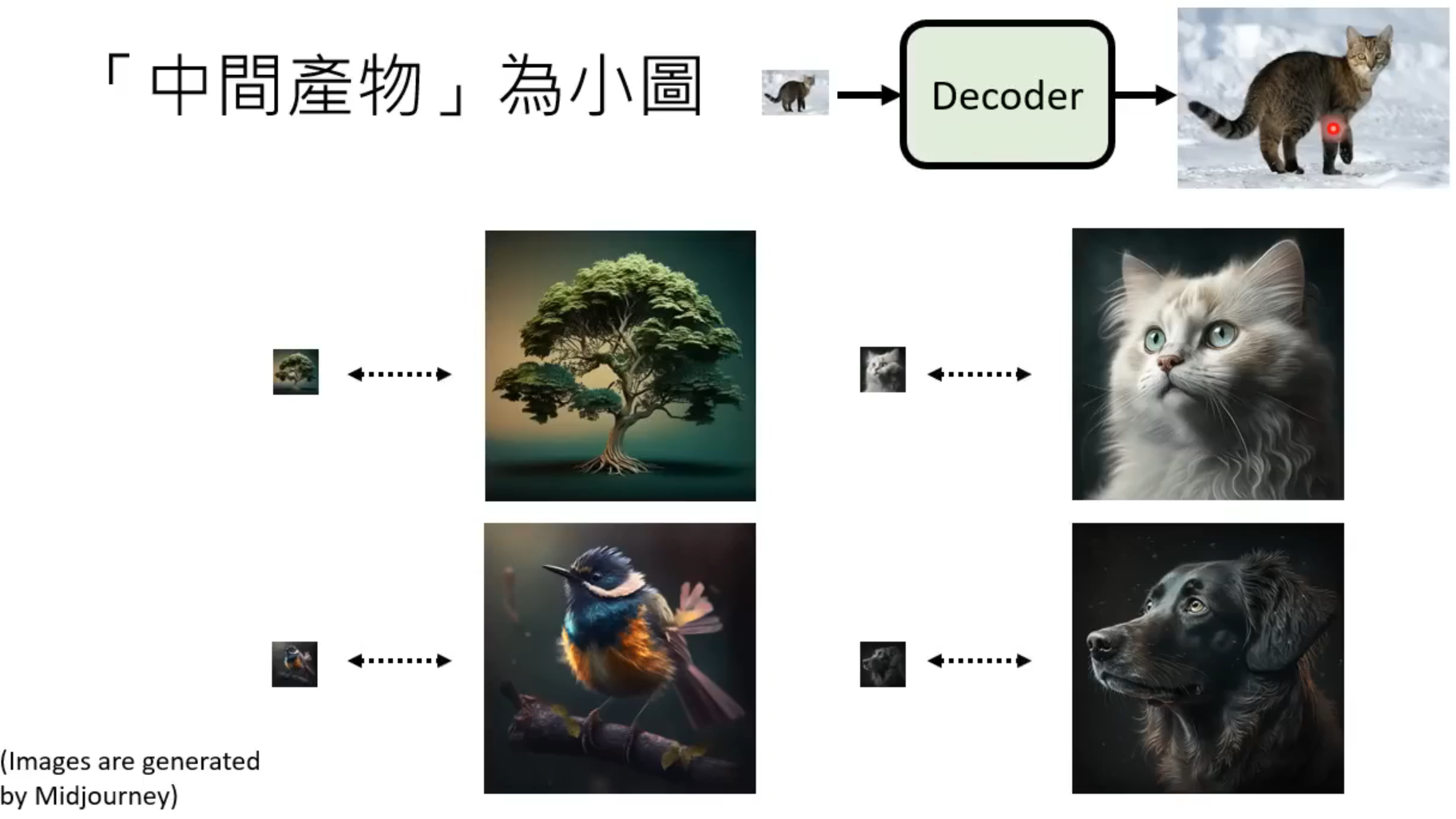
这种情况下只需要准备小图-大图成对的训练集即可
- 中间产物为Latent Representation(如:Stable Diffusion、Dall-E)
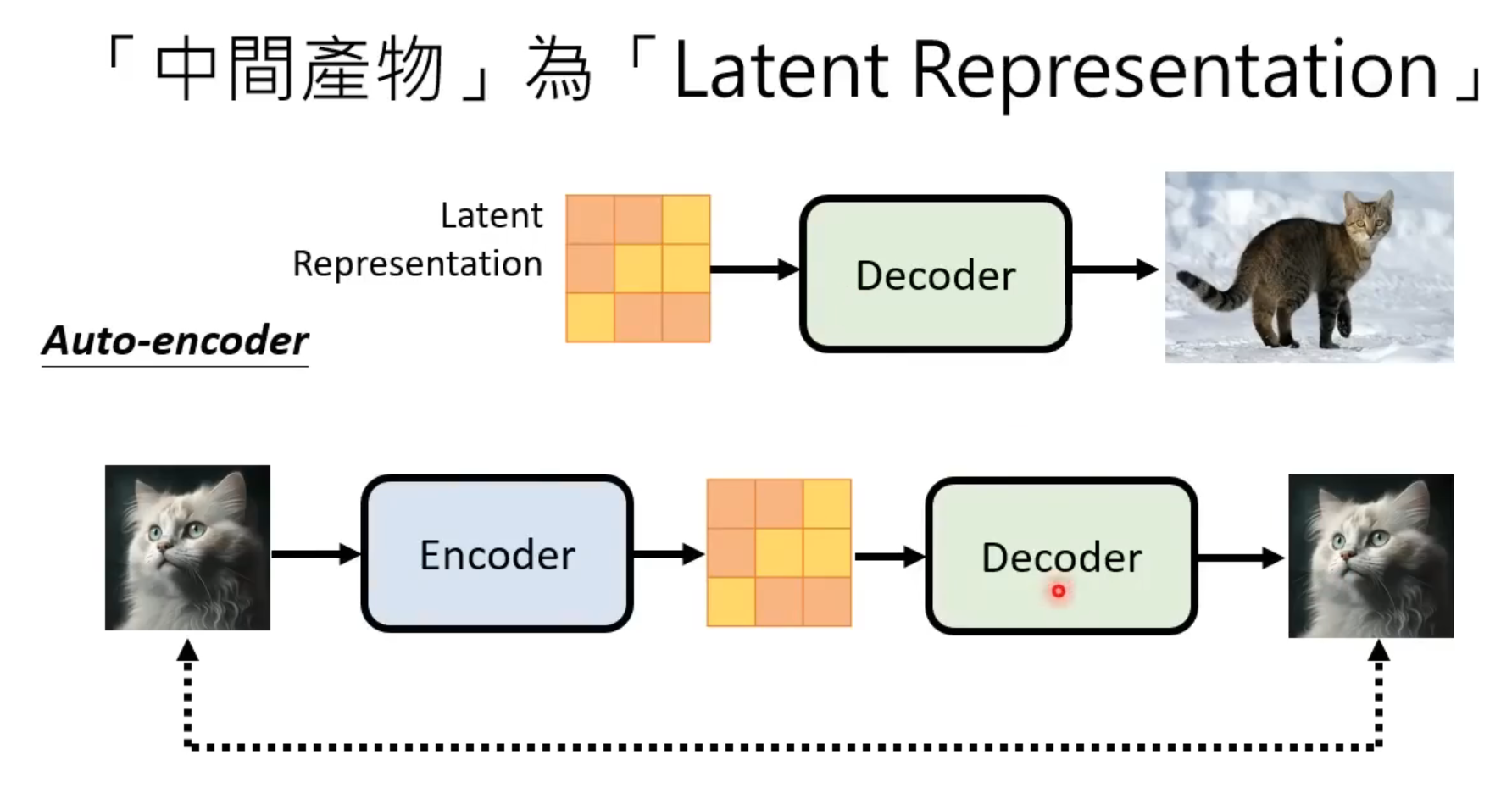
思路为训练一个auto-encoder,将原始图片通过encoder转换为向量,再通过Decoder将这个向量还原成对应的图片,调节decoder的参数,使得还原后的图片和原始的图片足够接近,这样就能将能够由向量生成图片的Decoder训练出来
2.
这三大元件通常是分开训练然后再组合到一起的
模型评估方法
1.FID
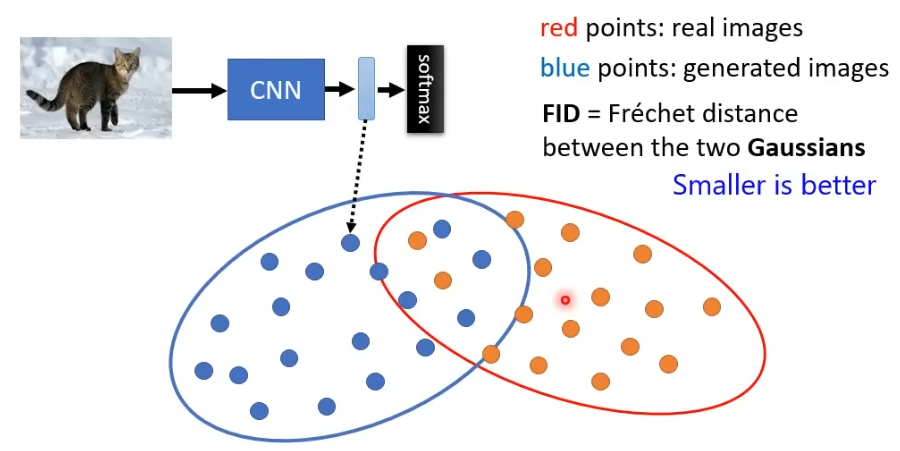
将真实图片和生成图片全部丢进基于CNN的图像分类系统中得到它们的representation,真实图片representation和生成图片的representation的距离代表其相似度,FID假设这两个represention都是高斯分布(正态分布),然后计算其Frechet Distance,距离越小代表模型效果越好
这种方法需要sample大量的image
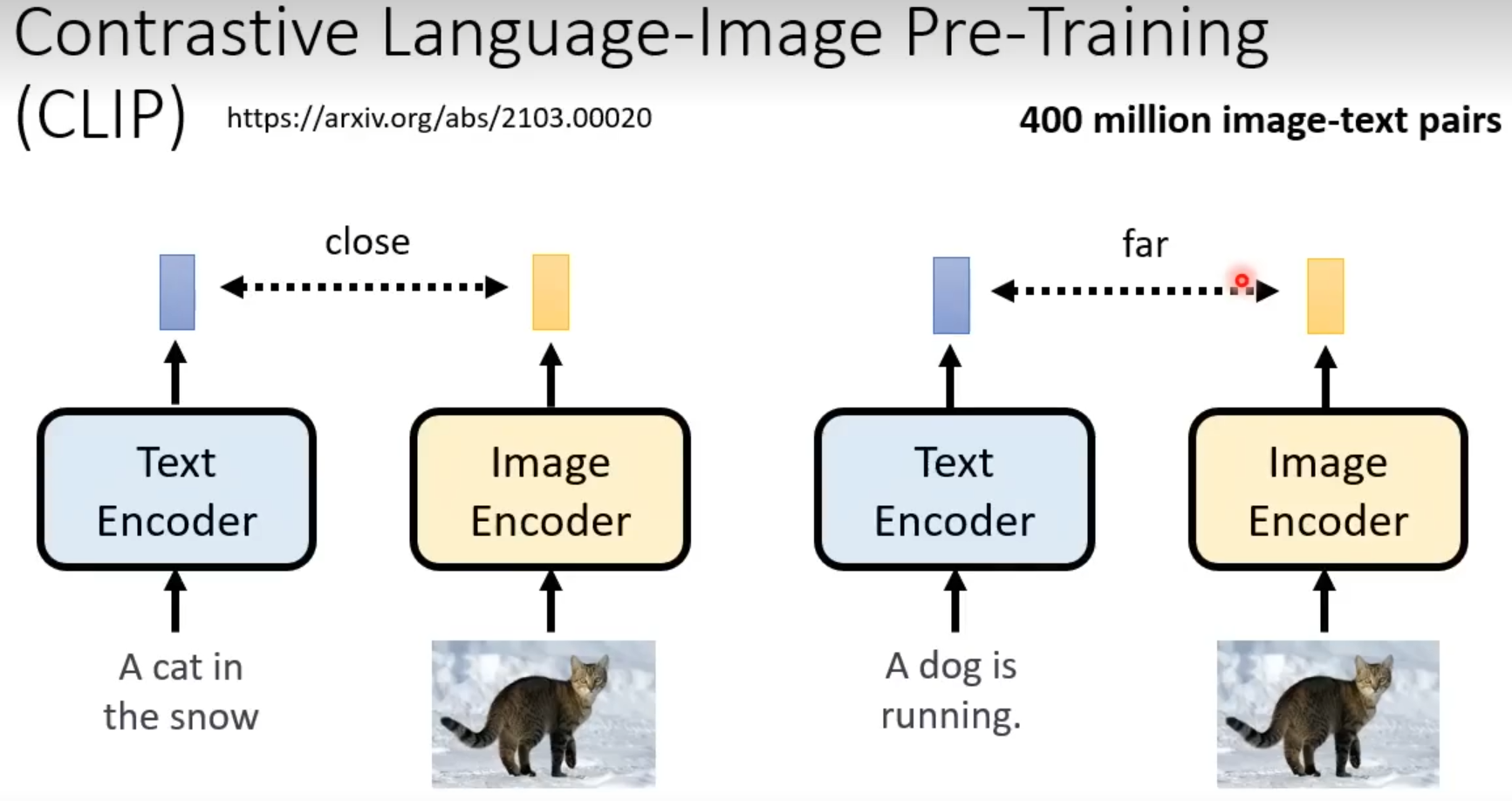
2.CLIP SCORE
CLIP:由400million的文字-图片对生成的模型,这个模型里面有Text Encoder和Image Encoder,Text Encoder可以输入一段文字产生一个向量,Image Encoder可以输入一张图片产生一个向量,判断文字和图片分别产生向量的距离即可判断模型是否生成了和文字对应的图片
Diffusion Model原理剖析
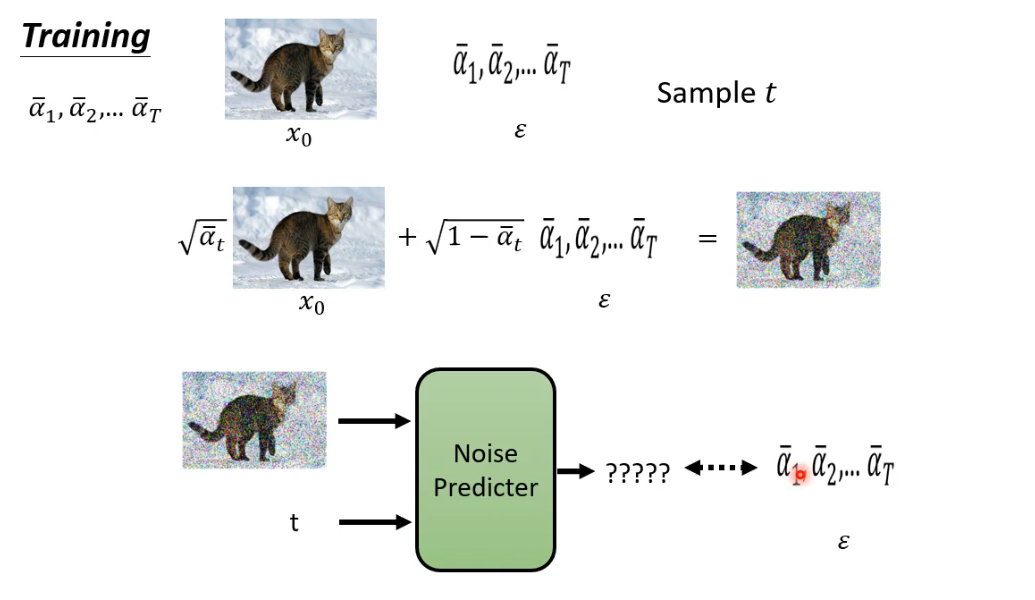
训练过程
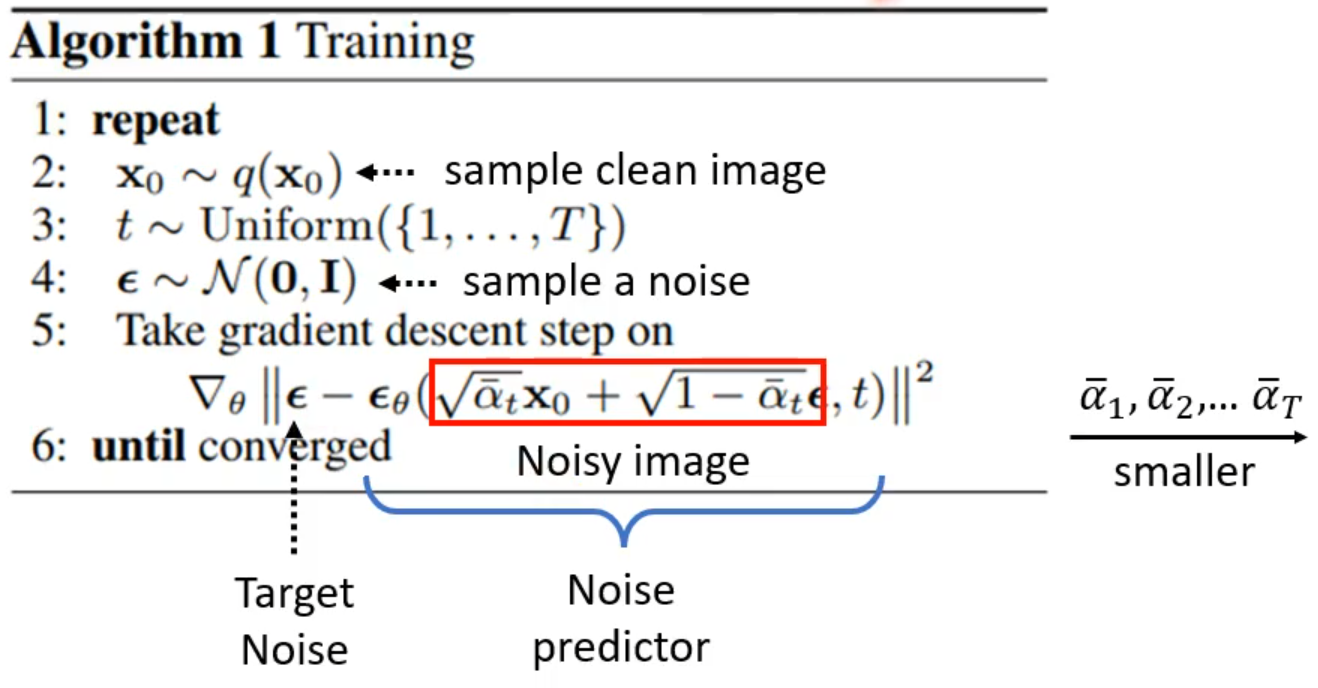
第一行:表示循环进行
第二行:从训练集中sample一张干净的图
第三行:从1~T随机抽取一个整数
第四行:从正态分布中随机抽取一个$\epsilon$,相当于随机生成一个噪声图片
第五行:执行梯度下降
t为前面抽取的随机数,$\alpha$
1,$\alpha$2,$\alpha$T为事先定好的参数,随着t的增大,$\alpha$T逐渐变小;x0为前面抽取的干净的图片,$\epsilon$表示抽取的噪声图片红色方框内表示:对x
0和进行加权求和,前面随机到的t越大,越小,表示原图片所占的比例越小,噪声图片所占的比例越大,即:t越大,噪声加的越多。红色方框内运算结束后得到的是一张加噪声后的图片Noisy Image$\epsilon$
$\theta$表示Noise Predicter函数,输入Noisy image和一个步骤数值t,输出一个noise,这一步的ground truth即为$\epsilon$这一步的图解为():
第六行:结束条件为收敛
运行过程
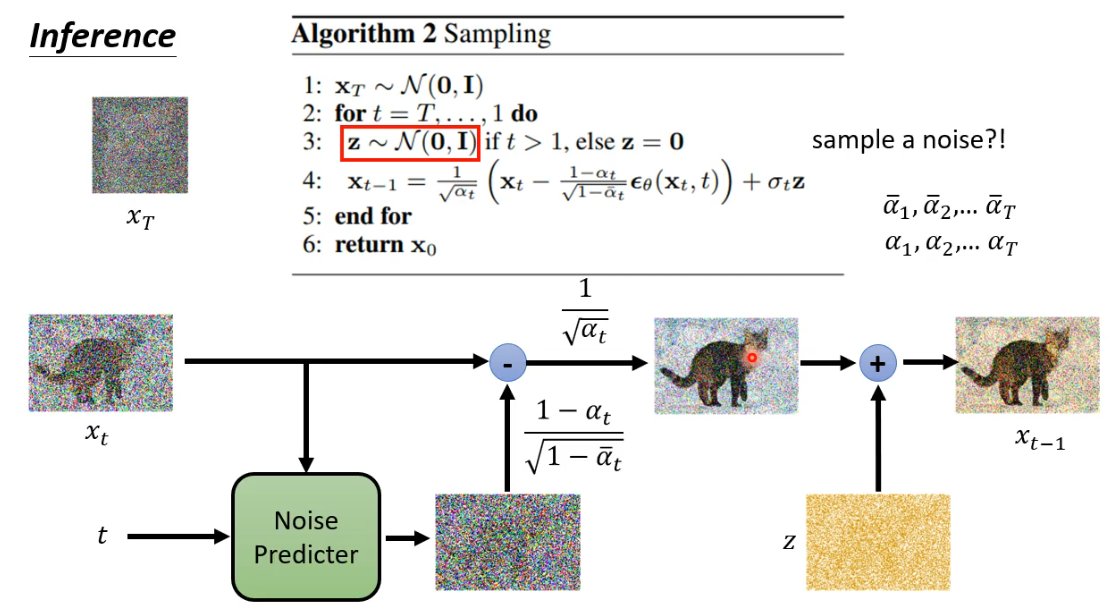
- 第一步:从正态分布中抽取一张噪声图片(为完全噪声)
- 第二步:表示t从T一直到1,循环T次
- 第三步:又从正态分布中抽取了一张另外的噪声图片z
- 第四步:由x
t得到xt-1
这一步首先准备了两组参数,如图中所示,
- 第五、六步为结束

